使用BN的原因和BN的原理
批归一化实际上是为了解决“Internal Covariate Shift”问题,即在深度神经网络在训练过程中使得每一层神经网络的输入保持相同分布。
其基本思想为:因为深度神经网络在做非线性变换前的激活输入值,在随着网络深度加深或者训练过程中,其分布逐渐发生偏移或者变动,这就导致”梯度消失“问题,从而训练收敛慢。
为什么会造成“梯度消失”问题?这是因为,变化的整体分布逐渐往非线性函数的取值区间的上下限两端靠近,我们可以观察sigmoid函数和tanh函数的图像,其上下限两端的梯度均接近0. 而接近上下限则会导致梯度接近0, 从而发生“梯度消失”现象。
因此,BN所做的事就是通过一定的规范化手段,把每层神经网络任意神经元的输入值分布强行拉回到均值为0,方差为1的标准正态分布。其中,$\epsilon$是为了控制分母为正。
然而,如果强行对数据进行缩放,可能会导致一些问题(毕竟强行改变了人家的分布),因此,BN增加了scale和shift的操作。其核心思想是找到一个线性和非线性的较好平衡点,既能享受非线性的较强表达能力的好处,又避免太靠非线性区两头使得网络收敛速度太慢。
既然BN的名称为batch normalization,那其表现就会受到batch size的影响:
- size太小,算出的$\mu$和$\sigma$不准确,影响归一化,导致性能下降;
- size太小,则内存放不下。
BN放置的位置
许多人会纠结Batch Normalization操作放置的位置,这里做一个确定性的结论:通常位于X=WU+B激活输入值获得之后,非线性函数变换(激活函数)之前,图示如下:

其他归一化手段
除了BN,还有layer normalization、Group Normalization和Instance Normalization。
我们参考susht师姐整理的内容进行总结:
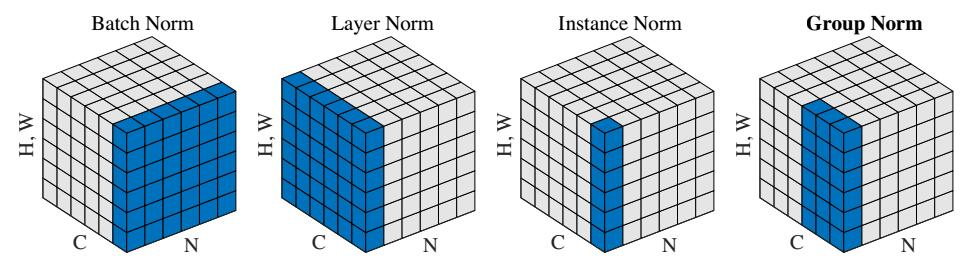
其实这些方法只是归一化的方向不一样,不再沿batch方向归一化,他们的不同点就在于归一化的方向不一样。
BN:批量归一化,往batch方向做归一化,归一化维度是[N,H,W]
LN:层次归一化,往channel方向做归一化,归一化维度为[C,H,W]
IN:实例归一化,只在一个channel内做归一化,归一化维度为[H,W]
GN:介于LN和IN之间,在channel方向分group来做归一化,归一化的维度为[C//G , H, W]
深度学习框架中使用BN
这里贴一下一点注意事项。
在pytorch中使用BN很简单,但注意,对应模型在训练和验证(测试)两种情况,需要区分model.train()和model.eval()。另外贴一下使用方法:
1 | nn.Conv2d(in_channel, out_channel, 3, stride, 1, bias=False) |
在tensorflow中BN的实现主要有三个:
- tf.nn.batch_normalization
- tf.layers.batch_normalization
- tf.contrib.layers.batch_norm
参考资料: