Attention用于NLP的小结
基本转载susht师姐的知乎博文,真是优秀的师姐啊,向她学习!
https://zhuanlan.zhihu.com/p/35739040
定义:参考Attention is All You Need中的说法,假设当前时刻t下,我们有一个query向量,和一段key向量,这里query可以理解为一个包含比较多信息的全局向量,我们利用这个query对所有key向量进行加权求和,学习到一个更合适的新向量去做分类或者预测等任务。
假设$q_t$是时刻$t$下的query,$K$是key,$k_s$是其中一个key向量,$v$是value矩阵。我们先对$q_t$$和每个key进行相似度计算得到一个非归一化的score分数:
这里用到了点乘,分母则是为了调整内积结果,使得内积不那么大,避免softmax结果过于专一。然后对score进行softmax归一化,作为attention概率权重:
最后我们对每个位置key所对应的权重和value进行加权求和,得到最终的输出向量:
对应到具体任务上可以理解更加清晰:
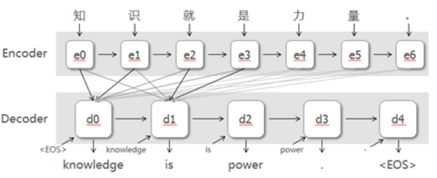
- 在机器翻译任务中,query可以定义成decoder中某一步的hidden state,key是encoder中每一步的hidden state,我们用每一个query对所有key都做一个对齐,decoder每一步都会得到一个不一样的对齐向量。
- 在文本分类任务中,query可以定义成一个可学的随机变量(参数),key就是输入文本每一步的hidden state,通过加权求和得到句向量,再进行分类。Attention机制用在文本分类中,我们可以看做是对句子进行加权,提高重要词语的注意力,减小其它词语的关注度。
根据Attention的计算区域
- Soft Attention: 这是比较常见的Attention方式,对所有key求权重概率,每个key都有一个对应的权重,是一种全局的计算方式(也可以叫Global Attention)
- Hard Attention: 这种方式是直接精准定位到某个key,其余key就都不管了,相当于这个key的概率是1,其余key的概率全部是0。因此这种对齐方式要求很高,要求一步到位,如果没有正确对齐,会带来很大的影响。另一方面,因为不可导,一般需要用强化学习的方法进行训练。(或者使用gumbel softmax之类的)
- Local Attention,这种方式其实是以上两种方式的一个折中,对一个窗口区域进行计算。先用Hard方式定位到某个地方,以这个点为中心可以得到一个窗口区域,在这个小区域内用Soft方式来算Attention。
根据Attention的所用信息
假设我们要对一段原文计算Attention,这里原文指的是我们要做attention的文本,那么所用信息包括内部信息和外部信息,内部信息指的是原文本身的信息,而外部信息指的是除原文以外的额外信息:
- General Attention:这种方式利用到了外部信息,常用于需要构建两段文本关系的任务,query一般包含了额外信息,根据外部query对原文进行对齐。
- Local Attention:这种方式只使用内部信息,key和value以及query只和输入原文有关,在self attention中,key=value=query。既然没有外部信息,那么在原文中的每个词可以跟该句子中的所有词进行Attention计算,相当于寻找原文内部的关系。
根据Attention的结构层次
分为单层attention,多层attention和多头attention:
- 单层Attention,这是比较普遍的做法,用一个query对一段原文进行一次attention。
- 多层Attention,一般用于文本具有层次关系(比如包括多个句子的文档)的模型,假设我们把一个document划分成多个句子,在第一层,我们分别对每个句子使用attention计算出一个句向量(也就是单层attention);在第二层,我们对所有句向量再做attention计算出一个文档向量(也是一个单层attention),最后再用这个文档向量去做任务。
- 多头Attention,这是Attention is All You Need中提到的multi-head attention,用到了多个query对一段原文进行了多次attention,每个query都关注到原文的不同部分,相当于重复做多次单层attention。
从模型方面看
Attention一般用在CNN和LSTM上,也可以直接进行纯Attention计算:
CNN+Attention:
CNN的卷积操作可以提取重要特征,也算是Attention的思想,但是CNN的卷积感受视野是局部的,需要通过叠加多层卷积区去扩大视野。另外,Max Pooling直接提取数值最大的特征,也像是hard attention的思想,直接选中某个特征。
可以应用这几个方面:
- 在卷积操作前做attention,比如Attention-Based BCNN-1,这个任务是文本蕴含任务需要处理两段文本,同时对两段输入的序列向量进行attention,计算出特征向量,再拼接到原始向量中,作为卷积层的输入。
- 在卷积操作后做attention,比如Attention-Based BCNN-2,对两段文本的卷积层的输出做attention,作为pooling层的输入。
- 在pooling层做attention,代替max pooling。比如Attention pooling,首先我们用LSTM学到一个比较好的句向量,作为query,然后用CNN先学习到一个特征矩阵作为key,再用query对key产生权重,进行attention,得到最后的句向量。
LSTM+Attention
LSTM内部有Gate机制,其中input gate选择哪些当前信息进行输入,forget gate选择遗忘哪些过去信息,这算是一定程度的Attention了,而且号称可以解决长期依赖问题,实际上LSTM需要一步一步去捕捉序列信息,在长文本上的表现是会随着step增加而慢慢衰减,难以保留全部的有用信息。
LSTM通常需要得到一个向量,再去做任务,常用的方式有:
- 直接使用最后的hidden state(可能会损失一定的前文信息,难以表达全文)
- 对所有step下的hidden state进行等权平均(对所有step一视同仁)
- Attention机制,对所有step的hidden state进行加权,把注意力集中到整段文本中比较重要的hidden state信息。性能比前面两种要好一点,而方便可视化观察哪些step是重要的,但是要小心过拟合,而且也增加了计算量。
纯Attention: Attention is all you need,没有用到CNN/RNN,乍一听也是一股清流了,但是仔细一看,本质上还是一堆向量去计算attention。
相似度计算方式
做attention时,我们需要计算query和某个key的相似度(分数),常用的方法有:
- 点乘:最简单的方法,$s(q,k) = q^Tk$
- 矩阵相乘:$s(q,k)=q^TWk$
- cos相似度:$s(q,k)=\frac{q^Tk}{||q||\cdot||k||}$
- 串联方式:把q,k拼接起来,$s(q,k)=W[q;k]$
- 用多层感知机:$s(q,k)=v^T_atanh(Wq+Uk)$
Attention适合的任务
- 长文本任务:document级别,因为长文本本身所携带的信息量比较大,可能会带来信息过载问题,很多任务可能只需要用到其中一些关键信息(比如文本分类),所以Attention机制用在这里正适合capture这些关键信息。
- 涉及到两段的相关文本,可能会需要对两段内容进行对齐,找到这两段文本之间的一些相关关系。比如机器翻译,将英文翻译成中文,英文和中文明显是有对齐关系的,Attention机制可以找出,在翻译到某个中文字的时候,需要对齐到哪个英文单词。又比如阅读理解,给出问题和文章,其实问题中也可以对齐到文章相关的描述,比如“什么时候”可以对齐到文章中相关的时间部分。
- 任务很大部分取决于某些特征。我举个例子,比如在AI+法律领域,根据初步判决文书来预测所触犯的法律条款,在文书中可能会有一些罪名判定,而这种特征对任务是非常重要的,所以用Attention来capture到这种特征就比较有用。(CNN也可以)
常见的task:
- 机器翻译:encoder用于对原文建模,decoder用于生成译文,attention用于连接原文和译文,在每一步翻译的时候关注不同的原文信息。
- 摘要生成:encoder用于对原文建模,decoder用于生成新文本,从形式上和机器翻译都是seq2seq任务,但是从任务特点上看,机器翻译可以具体对齐到某几个词,但这里是由长文本生成短文本,decoder可能需要capture到encoder更多的内容,进行总结。(对话系统也可)
- 图文互搜:encoder对图片建模,decoder生成相关文本,在decoder生成每个词的时候,用attention机制来关注图片的不同部分。
- 文本蕴含:判断前提和假设是否相关,attention机制用来对前提和假设进行对齐。
- 阅读理解:可以对文本进行self attention,也可以对文章和问题进行对齐。
- 文本分类:一般是对一段句子进行attention,得到一个句向量去做分类。
- 序列标注:Deep Semantic Role Labeling with Self-Attention,这篇论文在softmax前用到了self attention,学习句子结构信息,和利用到标签依赖关系的CRF进行pk。
- 关系抽取:也可以用到self attention
补充
我这次参加了百度常规赛:知识驱动对话,也是利用了Attention作为decoder的一部分,比赛效果还可以。之后再写一篇文章作为总结。