1x1卷积核
https://zhuanlan.zhihu.com/p/40050371


1x1卷积核作用
降维/升维:改变通道大小

增加非线性
1*1卷积核,可以在保持feature map尺度不变的(即不损失分辨率)的前提下大幅增加非线性特性(利用后接的非线性激活函数),把网络做的很deep。
备注:一个filter对应卷积后得到一个feature map,不同的filter(不同的weight和bias),卷积以后得到不同的feature map,提取不同的特征,得到对应的specialized neuron
跨通道信息交互(channal 的变换)
例子:使用1x1卷积核,实现降维和升维的操作其实就是channel间信息的线性组合变化,3x3,64channels的卷积核后面添加一个1x1,28channels的卷积核,就变成了3x3,28channels的卷积核,原来的64个channels就可以理解为跨通道线性组合变成了28channels,这就是通道间的信息交互[7]。
感受野计算
从底向上计算。
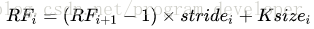
在卷积神经网络中,感受野(Receptive Field)的定义是卷积神经网络每一层输出的特征图(feature map)上的像素点在输入图片上映射的区域大小。
beam search
对于seq2seq,我们实际上是在建模
$p(Y|X)=p(Y_1|X)p(Y_2|X,Y_1)p(Y_3|X,Y_1,Y_2)p(Y_4|X,Y_1,Y_2,Y_3)…$
在解码时,我们希望能找到最大概率的$Y$。
- 贪心:如果我们在第一步$p(Y_1|X)$时,直接选择最大概率的(期望目标是$P$),然后代入第二步$p(Y_2|X,Y_1)$,再次选择最大概率$Y_2$,依次类推,每一步选择当前最大概率的输出,则称为贪心搜索,是一种最低成本的解码方案。但这种方案得到的结果未必是最优的,而假如第一步我们选择了概率不是最大的$Y_1$,代入第二步时也许会得到非常大的条件概率$p(Y_2|X,Y_1)$,从而两者乘积会超过逐位取最大的算法。
- beam search: 如果要枚举所有路径最优,其计算量是无法接受的。因此seq2seq使用了一种折中的方法:beam search。该方法的思想是:在每步计算时,只保留当前最优的topk个候选结果。比如取$topk=3$,则第一步时,只保留使得$p(Y_1|X)$最大的前三个$Y_1$,然后分别代入$p(Y_2|X,Y_1)$,然后各取前三个$Y_2$,这样就有了9个组合。这时候计算每一种组合的总概率,仍然只保留前三个,依次递归,直到出现第一个\
。普通贪心搜索相当于$topk=1$。
SVD分解原理
参考资料:https://www.cnblogs.com/pinard/p/6251584.html
文本主题模型-潜在语义索引(LSI)
参考资料:https://www.cnblogs.com/pinard/p/6805861.html
非负矩阵分解
https://www.cnblogs.com/pinard/p/6812011.html
LDA模型
https://www.cnblogs.com/pinard/p/6831308.html
RNN, LSTM
https://blog.csdn.net/zhaojc1995/article/details/80572098
TextCNN
https://www.cnblogs.com/bymo/p/9675654.html
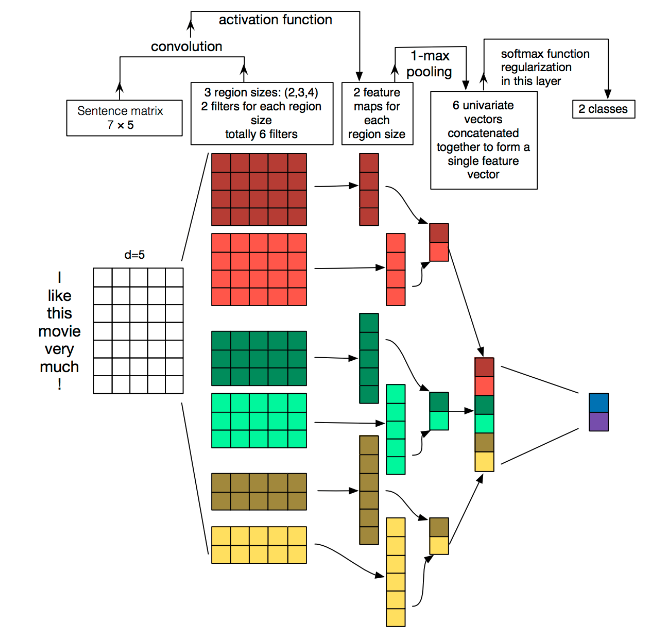
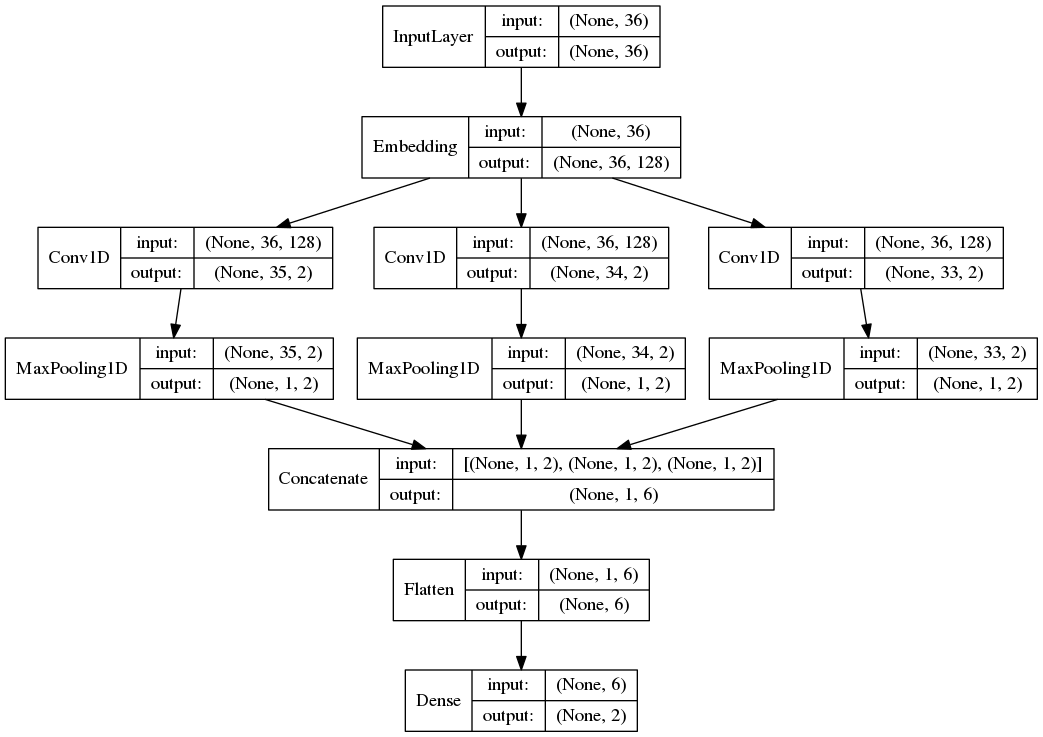
通道:
- 图像中可以利用(R,G,B)作为不同channel;
- 文本的输入的channel通常是不同方式的embedding方式(比如 word2vec或Glove),实践中也有利用静态词向量和fine-tunning词向量作为不同channel的做法
一维卷积(conv-1d):
- 图像是二维数据;
- 文本是一维数据,因此在TextCNN卷积用的是一维卷积(在word-level上是一维卷积;虽然文本经过词向量表达后是二维数据,但是在embedding-level上的二维卷积没有意义)一维卷积带来的问题是需要通过设计不同 kernel_size 的 filter 获取不同宽度的视野。
Pooling层:
A Convolutional Neural Network for Modelling Sentences 中将pooling层改成了(dynamic) k-max pooling,pooling阶段保留 k 个最大的信息,保留了全局的序列信息。
Word2vec
https://www.cnblogs.com/pinard/p/7160330.html
https://www.jianshu.com/p/471d9bfbd72f
https://zhuanlan.zhihu.com/p/35500923 (susht师姐讲得更好)
减少过拟合
- L1/L2正则化
- 交叉验证
- dropout
- 增大数据量
- 降低模型复杂度
- Batch Norm
- early stop
- bagging
解决梯度消失
- 修改激活函数
- Batch Norm
- 使用LSTM
- short cut 残差
数据不平衡
- 欠采样:去除一些样例使得类别均衡;代表型算法是利用集成学习机制,将反例划分为若干各集合供不同学习器使用,这样看起来对每个学习器都进行了欠采样,但在全局不会丢失重要信息。
- 过采样:生成合成数据的过程,试图学习少数类样本特征随机地生成新的少数类样本数据。最常见的技术为SMOTE算法,在少数类数据点的特征空间里,根据随机选择的一个K最近邻样本随机地合成新样本。
其他资料
玩转Keras之seq2seq自动生成标题 - 特别的一点,这个任务具有先验知识:标题中的大部分字词都在文章中出现过(注:仅仅是出现过,并不一定是连续出现,更不能说标题包含在文章中,不然就成为一个普通的序列标注问题了)。因此,可以将文章中的词集作为一个先验分布,加到解码过程的分类模型中,使得模型在解码输出时更倾向选用文章中已有的字词。

- 文本多分类踩过的坑: 又是susht师姐的文章。很详细的记录了一些文本多分类时的问题,值得深入思考。
- 贝叶斯估计、极大似然估计、最大后验估计: