本文记录一些关于预训练语言模型讲解比较好的中文博客,有时间再补充自己的理解。
预训练方式
传统的模型预训练手段就是语言模型,比如ELMo模型就是以BiLSTM为基础架构、用两个方向的语言模型分别预训练两个方向的LSTM的;后面的OpenAI的GPT、GPT-2也是用标准的、单向的语言模型来预训练。
之后还有更多的预训练方式,比如BERT使用了称为”掩码语言模型(Masked Language Model)”的方式来预训练;而XLNet提出的为更彻底的”Permutation Language Modeling”,称为“乱序语言模型”;还有UNILM模型,直接用当个BERT架构做Seq2seq等等。
ELMO
https://zhuanlan.zhihu.com/p/88993965 最大的优点是动态词向量,同一个词,出现在不同的语境中,会有不同的词向量。
分开训练两个语言模型,即正向语言模型和反向语言模型,将对应字通过正向与反向语言模型得到的vector拼接。
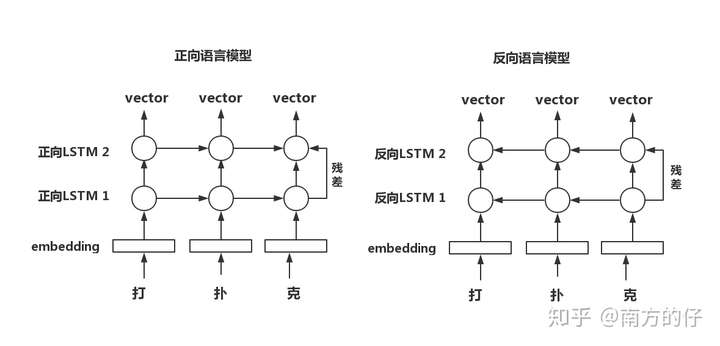
GPT
OpenAI Transformer是一类可迁移到多种NLP任务的,基于Transformer的语言模型。它的基本思想同ULMFiT相同,都是在尽量不改变模型结构的情况下将预训练的语言模型应用到各种任务。不同的是,OpenAI Transformer主张用Transformer结构,而ULMFiT中使用的是基于RNN的语言模型。文中所用的网络结构如下:
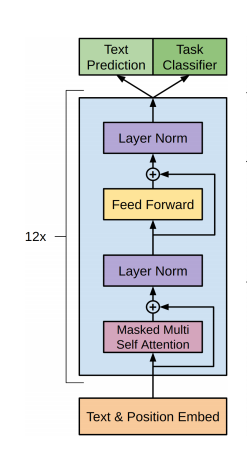
模型的训练过程分为两步:
Unsupervised pre-training :第一阶段的目标是预训练语言模型,给定tokens的语料,目标函数为最大化似然函数:
该模型中应用multi-head self-attention,并在之后增加position-wise的前向传播层,最后输出一个分布:
Supervised fine-tuning :有了预训练的语言模型之后,对于有标签的训练集,给定输入序列$x^1,x^2,…,x^m$和标签$y$,可以通过语言模型得到$h_l^m$,经过输出层后对$y$进行预测:
目标函数为:
则整个任务的目标函数为:
fasttext
模型架构
其中$x_1,x_2,…,x_{N-1},x_N$表示一个文本中的n-gram向量,每个特征是词向量的平均值。这和前文中提到的cbow相似,cbow用上下文去预测中心词,而此处用全部的n-gram去预测指定类别。
层次softmax
对于有大量类别的数据集,fasttext使用了一个分层分类器。不同的类别被整合进树形结构中(想象下二叉树而非 list)。在某些文本分类任务中类别很多,计算线性分类器的复杂度高。为了改善运行时间,fastText 模型使用了层次 Softmax 技巧。层次 Softmax 技巧建立在哈弗曼编码的基础上,对标签进行编码,能够极大地缩小模型预测目标的数量。
fastText 也利用了类别(class)不均衡这个事实(一些类别出现次数比其他的更多),通过使用 Huffman 算法建立用于表征类别的树形结构。因此,频繁出现类别的树形结构的深度要比不频繁出现类别的树形结构的深度要小,这也使得进一步的计算效率更高。
fastText适合类别非常多的分类问题,如果类别比较少,容易过拟合。
在fastText中,由于最终的输出是预测句子的标签,这是一个监督学习过程,所以在训练过程中已经知道了要计算哪一条路径的概率,这样在计算霍夫曼树的路径时只需要计算一条路径而不用计算全部路径,大大提高了计算效率,而在测试过程中,由于没有标签,不知道真实的路径,仍然需要将霍夫曼树的每一个叶节点对应的路径的概率算出来。
与word2vec的区别:
- 相似处:
- 图模型结构很像,都是采用embedding向量的形式,得到word的隐向量表达。
- 都采用很多相似的优化方法,比如使用Hierarchical softmax优化训练和预测中的打分速度。
- 不同处:
- 模型的输出层:word2vec的输出层,对应的是每一个term,计算某term的概率最大;而fasttext的输出层对应的是分类的label。不过不管输出层对应的是什么内容,其对应的vector都不会被保留和使用。
- 模型的输入层:word2vec的输出层,是 context window 内的term;而fasttext 对应的整个sentence的内容,包括term,也包括 n-gram的内容。
- 两者本质的不同,体现在 h-softmax的使用:
- Word2vec的目的是得到词向量,该词向量最终是在输入层得到,输出层对应的 h-softmax也会生成一系列的向量,但最终都被抛弃,不会使用。
- fastText则充分利用了h-softmax的分类功能,遍历分类树的所有叶节点,找到概率最大的label(一个或者N个)
- fastText是是一个文本分类算法,是一个有监督模型,有额外标注的标签;CBOW是一个训练词向量的算法,是一个无监督模型,没有额外的标签,其标准是语料本身,无需额外标注。
ULMFiT 源码值得学习
ULMFiT是一种有效的NLP迁移学习方法,核心思想是通过精调预训练的语言模型完成其他NLP任务。文中所用的语言模型参考了Merity et al. 2017a的AWD-LSTM模型,即没有attention或shortcut的三层LSTM模型。
ULMFit的过程分三步:
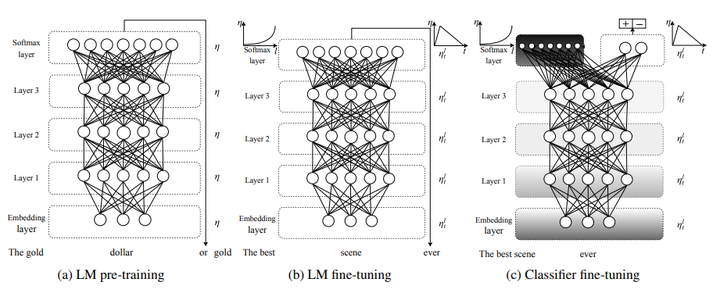
General-domain LM pre-train
在Wikitext-103上进行语言模型的预训练。
预训练的语料要求:large & capture general properties of language
- 预训练对小数据集十分有效,之后仅有少量样本就可以使模型泛化。
Target task LM fine-tuning
Discriminative fine-tuning: 因为网络中不同层可以捕获不同类型的信息,因此在精调时也应该使用不同的learning rate。作者为每一层赋予一个学习率$\delta^l$,实验后发现,首先通过精调模型的最后一层L确定学习率$\delta^L$,递推地选择上一层学习率进行精调的效果最好,递推公式为$\delta^{l-1}=\delta^l / 2.6$
Slanted triangular learning rates(STLR)
为了针对特定任务选择参数,理想情况下需要在训练开始时让参数快速收敛到一个合适的区域,之后进行精调。为了达到这种效果,作者提出STLR方法,即让LR在训练初期短暂递增,在之后下降。
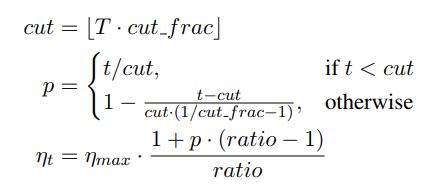
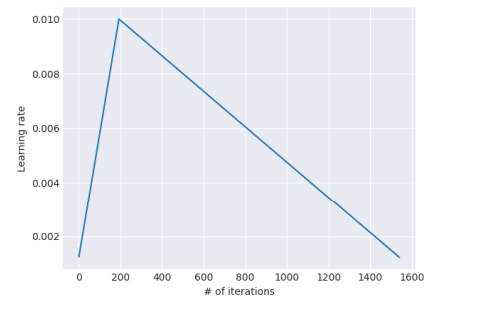
Target task classifier fine-tuning
为了完成分类任务的精调,作者在最后一层添加了两个线性block,每个都有batch-norm和dropout,使用ReLU作为中间层激活函数,最后经过softmax输出分类的概率分布。
ULMFit适用领域:分类
BERT
https://zhuanlan.zhihu.com/p/46652512
模型结构
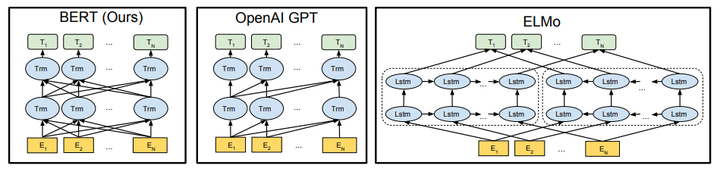
对比OpenAI GPT(Generative pre-trained transformer),BERT是双向的Transformer block连接;就像单向rnn和双向rnn的区别,直觉上来讲效果会好一些。
对比ELMo,虽然都是“双向”,但目标函数其实是不同的。ELMO是实际上是以$P(w_i|w1,…,w_{i-1})$和$P(w_i|w_{i+1},…w_n)$作为目标函数,独立训练出两个representation然后拼接,而BERT则是以$P(w_i|w_1,…,w_{i-1},w_{i+1},…,w_n)$作为目标函数训练LM。
Embedding
embedding是由三种embedding求和而成:
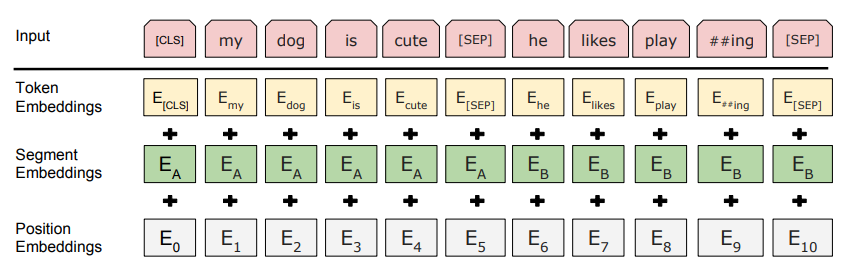
其中:
- Token Embeddings是词向量,第一个单词是CLS标志,可以用于之后的分类任务
- Segment Embeddings用来区别两种句子,因为预训练不光做LM还要做以两个句子为输入的分类任务
- Position Embeddings和之前文章中的Transformer不一样,不是三角函数而是学习出来的
预训练任务1-Masked LM
第一步预训练的目标就是做语言模型,从上文模型结构中看到了这个模型的不同,即bidirectional。
为什么要这样做bidirectional,作者的解释如下:
如果使用预训练模型处理其他任务,那人们想要的肯定不止某个词左边的信息,而是左右两边的信息。而考虑到这点的模型ELMo只是将left-to-right和right-to-left分别训练拼接起来。直觉上来讲我们其实想要一个deeply bidirectional的模型,但是普通的LM又无法做到,因为在训练时可能会“穿越”。所以作者用了一个加mask的trick。
在训练过程中作者随机mask 15%的token,而不是把像cbow一样把每个词都预测一遍。最终的损失函数只计算被mask掉那个token。Mask如何做也是有技巧的,如果一直用标记[MASK]代替(在实际预测时是碰不到这个标记的)会影响模型,所以随机mask的时候10%的单词会被替代成其他单词,10%的单词不替换,剩下80%才被替换为[MASK]。要注意的是Masked LM预训练阶段模型是不知道真正被mask的是哪个词,所以模型每个词都要关注。
预训练任务2-Next Sentence Prediction
因为涉及到QA和NLI之类的任务,增加了第二个预训练任务,目的是让模型理解两个句子之间的联系。训练的输入是句子A和B,B有一半的几率是A的下一句,输入这两个句子,模型预测B是不是A的下一句。
作者特意说了语料的选取很关键,要选用document-level的而不是sentence-level的,这样可以具备抽象连续长序列特征的能力。
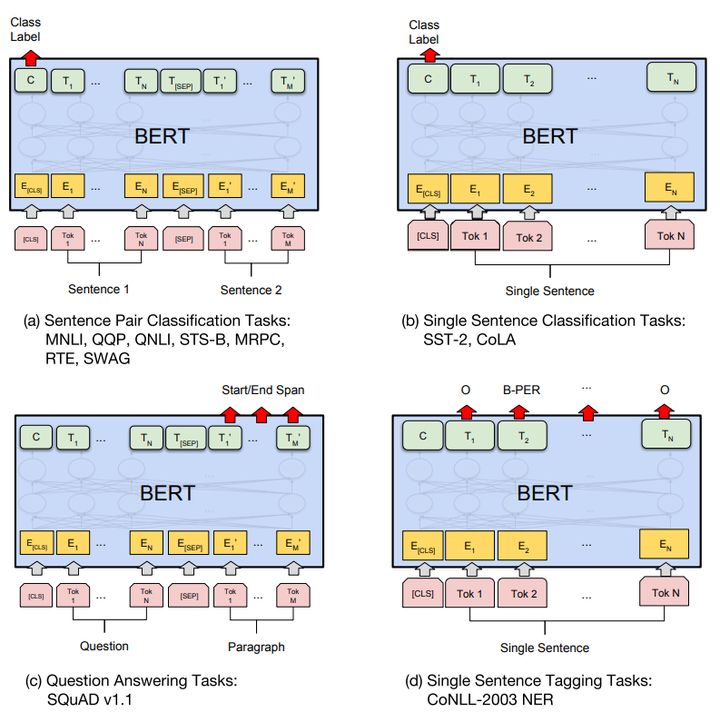
Fine-tunning
分类:对于sequence-level的分类任务,BERT直接取第一个[CLS]token的final hidden state $C\in \mathbb{R}H$,加一层权重$W$后softmax预测label proba:
与文本中已有的其它字/词相比,这个无明显语义信息的符号会更“公平”地融合文本中各个字/词的语义信息。
BERT缺点
- 预训练阶段因为采取引入[Mask]标记来Mask掉部分单词的训练模式,而Fine-tuning阶段是看不到这种被强行加入的Mask标记的,所以两个阶段存在使用模式不一致的情形,这可能会带来一定的性能损失;
- Bert在第一个预训练阶段,假设句子中多个单词被Mask掉,这些被Mask掉的单词之间没有任何关系,是条件独立的,而有时候这些单词之间是有关系的,XLNet则考虑了这种关系。
XLNet
参考:https://zhuanlan.zhihu.com/p/70257427
针对GPT/ELMO进行对比:使用到的是自回归语言模型(Autoregressive LM),即通常所讲的根据上文内容预测下一个可能跟随的单词。GPT 就是典型的自回归语言模型。ELMO尽管看上去利用了上文,也利用了下文,但是本质上仍然是自回归LM。
针对BERT进行对比:Bert通过在输入X中随机Mask掉一部分单词,然后预训练过程的主要任务之一是根据上下文单词来预测这些被Mask掉的单词,类似这种预训练模式被称为DAE LM。其缺点是在输入侧引入[Mask]标记,导致预训练阶段和Fine-tuning阶段不一致的问题,因为Fine-tuning阶段是看不到[Mask]标记的。
XLNet的出发点就是:能否融合自回归LM和DAE LM两者的优点。就是说如果站在自回归LM的角度,如何引入和双向语言模型等价的效果;如果站在DAE LM的角度看,它本身是融入双向语言模型的,如何抛掉表面的那个[Mask]标记,让预训练和Fine-tuning保持一致。
原理
XLNet仍然遵循两阶段的过程,第一个阶段是语言模型预训练阶段;第二阶段是任务数据Fine-tuning阶段。
它主要希望改动第一个阶段,就是说不像Bert那种带Mask符号的Denoising-autoencoder的模式,而是采用自回归LM的模式。也就是,能够比较充分地在自回归语言模型中,引入双向语言模型。即看上去输入句子$X$仍然是自左向右的输入,看到$T_i$单词的上文context_before,来预测$T_i$这个单词;但又希望在context_before里,不仅仅看到上文单词,也能看到$T_i$单词后面的下文context_after中的下文单词。
Permutation Language Model
这个部分是XLNet的主要理论创新。
如何解决的思路:XLNet在预训练阶段,引入Permutation Language Model的训练目标。即,比如包含单词$T_i$的当前输入句子$X$,由顺序的几个单词构成,比如$x_1,x_2,x_3,x_4$四个单词顺序构成。我们假设,要预测的单词$T_i$是$x_3$,位置在position 3,我们希望在context_before中也能看到position 4的单词$x_4$。因此可以这么做:假设我们固定住$x_3$所在位置,然后随机排列组合句子中的4个单词,在随机排列组合后的各种可能里再选择一部分作为模型预训练的输入$X$。 比如,随机排列组合后,抽取出$x_4,x_2,x_3,x_1$这一个排列组合作为模型的输入$X$。这就是XLNet的基本思想。
难点是如何实现上述思想:首先要强调,尽管上面讲的是把句子X的单词排列组合后,再随机抽取例子作为输入,但是,实际上你是不能这么做的,因为Fine-tuning阶段你不可能也去排列组合原始输入。所以,必须让预训练阶段的输入部分,看上去仍然是x1,x2,x3,x4这个输入顺序,但是可以在Transformer部分做些工作,来达成希望的目标。其实,就是利用了Transformer内部的Attention mask掩码。通过Attention Mask,把其它没有被选到的单词Mask掉,不让它们在预测单词Ti的时候发生作用,如此而已。一个简单图示:

假设随机的一种生成顺序为“\->迎->京->你->欢->北->\
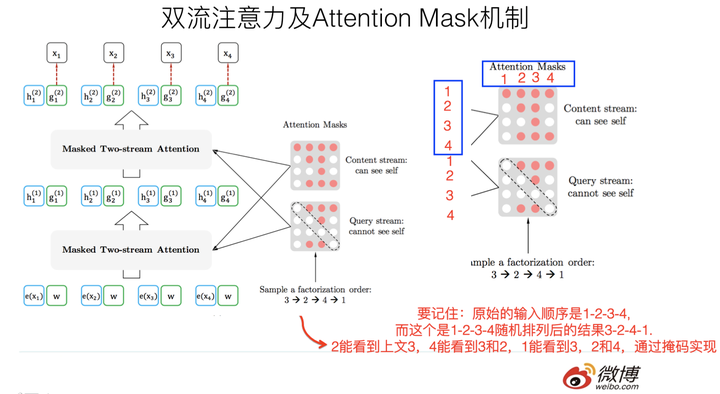
评论
XLNet开启了自回归语言模型如何引入下文的一个思路,相信对于后续工作会有启发。当然,XLNet不仅仅做了这些,它还引入了其它的因素,也算是一个当前有效技术的集成体。
感觉XLNet就是Bert、GPT 2.0和Transformer XL的综合体变身,首先,它通过PLM预训练目标,吸收了Bert的双向语言模型;然后,GPT2.0的核心其实是更多更高质量的预训练数据,这个明显也被XLNet吸收进来了;再然后,Transformer XL的主要思想也被吸收进来,它的主要目标是解决Transformer对于长文档NLP应用不够友好的问题。
与BERT的预训练过程的异同
区别主要在于:Bert是直接在输入端显示地通过引入Mask标记,在输入侧隐藏掉一部分单词,让这些单词在预测的时候不发挥作用,要求利用上下文中其它单词去预测某个被Mask掉的单词;而XLNet则抛弃掉输入侧的Mask标记,通过Attention Mask机制,在Transformer内部随机Mask掉一部分单词(这个被Mask掉的单词比例跟当前单词在句子中的位置有关系,位置越靠前,被Mask掉的比例越高,位置越靠后,被Mask掉的比例越低),让这些被Mask掉的单词在预测某个单词的时候不发生作用。本质上两者并没什么太大的不同,只是Mask的位置,Bert更表面化一些,XLNet则把这个过程隐藏在了Transformer内部而已。这样,就可以抛掉表面的[Mask]标记,解决它所说的预训练里带有[Mask]标记导致的和Fine-tuning过程不一致的问题。
XLNet这种改造,维持了表面看上去的自回归语言模型的从左向右的模式,这个Bert做不到,这个有明显的好处,就是对于生成类的任务,能够在维持表面从左向右的生成过程前提下,模型里隐含了上下文的信息。所以看上去,XLNet貌似应该对于生成类型的NLP任务,会比Bert有明显优势。另外,因为XLNet还引入了Transformer XL的机制,所以对于长文档输入类型的NLP任务,也会比Bert有明显优势。
XLNet起作用的三个因素
- 新的预训练目标:Permutation Language Model。这个可以理解为在自回归LM模式下,如何采取具体手段,来融入双向语言模型。这个是XLNet在模型角度比较大的贡献,确实也打开了NLP中两阶段模式潮流的一个新思路。
- 引入了Transformer-XL的主要思路:相对位置编码以及分段RNN机制。实践已经证明这两点对于长文档任务是很有帮助的;
- 加大增加了预训练阶段使用的数据规模;
接下来摘抄一下张俊林老师的结论:
XLNet综合而言,效果是优于Bert的,尤其是在长文档类型任务,效果提升明显。Bert生成做不好根本还是预训练的mask模式同时看到上文和下文,decoder没法达到这一点,原因应该还是在mask这种模式上.
ALBERT
参考:https://blog.csdn.net/u012526436/article/details/101924049
相对于BERT的改进
ALBERT也是采用和BERT一样的Transformer的encoder结果,激活函数使用的也是GELU。我们规定几个参数,词的embedding我们设置为E,encoder的层数我们设置为L,hidden size即encoder的输出值的维度我们设置为H,前馈神经网络的节点数设置为4H,attention的head个数设置为H/64。
在ALBERT中主要有三个改进方向。
对Embedding因式分解
在BERT中,词embedding与encoder输出的embedding维度是一样的都是768。但是ALBERT认为,词级别的embedding是没有上下文依赖的表述,而隐藏层的输出值不仅包括了词本生的意思还包括一些上下文信息,理论上来说隐藏层的表述包含的信息应该更多一些,因此应该让H>>E,所以ALBERT的词向量的维度是小于encoder输出值维度的。
在NLP任务中,通常词典都会很大,embedding matrix的大小是E×V,如果和BERT一样让H=E,那么embedding matrix的参数量会很大,并且反向传播的过程中,更新的内容也比较稀疏。
结合上述说的两个点,ALBERT采用了一种因式分解的方法来降低参数量。首先把one-hot向量映射到一个低维度的空间,大小为E,然后再映射到一个高维度的空间,说白了就是先经过一个维度很低的embedding matrix,然后再经过一个高维度matrix把维度变到隐藏层的空间内,从而把参数量从O(V×H)降低到了O(V×E+E×H),当E<<H时参数量减少的很明显。
跨层的参数共享(Cross-layer parameters)
在ALBERT还提出了一种参数共享的方法,Transformer中共享参数有多种方案,只共享全连接层,只共享attention层,ALBERT结合了上述两种方案,全连接层与attention层都进行参数共享,也就是说共享encoder内的所有参数,同样量级下的Transformer采用该方案后实际上效果是有下降的,但是参数量减少了很多,训练速度也提升了很多。
句间连贯(Inter-sentence coherence loss)
BERT的NSP任务实际上是一个二分类,训练数据的正样本是通过采样同一个文档中的两个连续的句子,而负样本是通过采用两个不同的文档的句子。该任务主要是希望能提高下游任务的效果,例如NLI自然语言推理任务。但是后续的研究发现该任务效果并不好,主要原因是因为其任务过于简单。NSP其实包含了两个子任务,主题预测与关系一致性预测,但是主题预测相比于关系一致性预测简单太多了,并且在MLM任务中其实也有类型的效果。
在ALBERT中,为了只保留一致性任务去除主题识别的影响,提出了一个新的任务 sentence-order prediction(SOP)。SOP因为是在同一个文档中选的,其只关注句子的顺序并没有主题方面的影响。并且SOP能解决NSP的任务,但是NSP并不能解决SOP的任务,该任务的添加给最终的结果提升了一个点。
移除dropout
ALBERT在训练了100w步之后,模型依旧没有过拟合,于是乎作者果断移除了dropout,没想到对下游任务的效果竟然有一定的提升。这也是业界第一次发现dropout对大规模的预训练模型会造成负面影响。
总结
ALBERT实际上是通过参数共享的方式降低了内存,预测阶段还是需要和BERT一样的时间,如果采用了xxlarge版本的ALBERT,那实际上预测速度会更慢。
ALBERT解决的是训练时候的速度提升,如果要真的做到总体运算量的减少,的确是一个复杂且艰巨的任务,毕竟鱼与熊掌不可兼得。不过话说回来,ALBERT也更加适合采用feature base或者模型蒸馏等方式来提升最终效果。
Transformer-XL
- XL是”extra-long”的意思,即Transformer-XL做了长度延伸的工作;
- Transformer规定输入大小为512,原始的输入需要进行裁剪或者填充,即将一个长的文本序列截断为几百个字符的固定长度片段,然后分别处理每个片段;这存在着文章跨片段依赖不能学习到的问题,也限制了长距离依赖。因此,提出Transformer-XL。
- Transformer-XL所做改进:
- 与Transformer的基本思路相同,Transformer-XL仍然是使用分段的方式进行建模,但其的本质不同时引入了段与段之间的循环机制,使得当前段在建模的时候能够利用之前段的信息来实现长期依赖性。(简略版:使用分段RNN且存储上一次处理的片段信息)
- 为了适应分段的情况,提出了相对位置编码方案。
ERNIE(百度)
主要改进是在mask的机制上做了改进,它的mask不是基本的word piece的mask,而是在pretraining阶段增加了外部的知识,由三种level的mask组成,分别是basic-level masking(word piece)+phrase level masking(WWM style) + entity level masking。在此基础上,借助百度在中文社区的强大能力,中文的ERNIE还使用了各种异质的数据集。另外为了适应多轮的贴吧数据,所以ERNIE引入了DLM(Dialogue Language Model)任务。

Knowledge masking
ERNIE的mask的策略是通过三个阶段学习的,在第一个阶段,采用的是BERT的模式,用的是basic-level masking,然后加入词组的mask(phrase-level masking),然后再加入实体级别(entity-level的mask)。

Heterogeneous Corpus Pre-training
训练集包括:Chinese Wiki, Baidu Baike, Baidu news, Baidu Tieba.
DLM(Dialogue Language Model) task
对话的数据对语义表示很重要,因为对于相同回答的提问一般都是具有类似语义的,ERNIE修改BERT的输入形式,使之能够使用多轮对话的形式,采用的是三个句子的组合[CLS]S1[SEP]S2[SEP]S3[SEP]的格式。这种组合可以表示多轮对话,例如QRQ、QRR、QQR。为了表示dialogue的属性,句子添加了dialog embedding组合,这个和segment embedding很类似。

- DLM还增加了任务来判断这个多轮对话是真的还是假的。
NSP+MLM
在贴吧外多轮对话数据外都采用普通的NSP+MLM的预训练任务。
ERNIE2.0
动机:在学习一个新语言的时候,我们需要很多之前的知识,在这些知识的基础上,我们可以获取对其他的任务的学习有迁移学习的效果。百度不满足于堆叠任务,而是提出了一个持续学习的框架。利用这个框架,模型可以持续添加任务但又不降低之前任务的精度,从而能够更好更有效地获得词法lexical、句法syntactic和语义semantic上的表达。

其在ERNIE1.0的基础上,利用大量数据和先验知识,提出了多个任务,用来做预训练,最后根据特定任务fine-tune。框架的提出是针对life-long learning,即终生学习,因为我们的任务叠加不是一次性进行的(multi-tasking learning),而是持续学习(continual pretraining)。因此为避免模型在学了新的任务后忘记旧任务,即旧的任务上loss变高,因此百度提出了一个包含pretraining和fine-tuning的持续学习框架。

Continual pre-training
任务的构建
百度把语言模型的任务归为三大类,包括字层级的任务(word-aware pretraining)、句结构层级的任务(structure-aware pretraining task)和语义层级的任务(semantic-aware pretraining task)。
持续的多任务学习
需要攻克两个难点:
- 如何保证模型不忘记之前的任务:常规的持续学习框架采用的是一个任务接一个任务的训练,这样导致的后果是模型在最新的任务上得到了好效果但在之前的任务获得差效果(knowledge retention)。
- 模型如何有效地训练:有人提出有新的任务进行,则从头开始训练一个新模型,但这样效率很低。
百度提出的方案(sequential multi-task learning):复用之前学到的模型的参数作为初始化,然后再训练。但这样似乎训练效率不够高,因为我们还是要每一轮都要同时训练多个任务。因此百度的解决方案是:框架自动在训练的过程中为每个任务安排训练N轮。
- 初始化optimized initialization: 每次有新任务过来,持续学习的框架使用的之前学习到的模型参数作为初始化,然后将新的任务与旧的任务一起训练;
- 训练任务安排task allocating: 对于多个任务,框架将自动地为每个任务在模型训练的不同阶段安排N个训练轮次,这样保证了有效率地学习到多任务。(部分任务的语义信息建模适合递进式,比如ernie1.0突破完形填空,ernie2.0突破选择题、句子排序题等,适合递进式的语音建模任务。)
Continual Fine-tuning
在模型预训练完成后,可以根据特定任务进行fine-tuning,这个和BERT一样。
模型架构

模型的结构和BERT一致,但在预训练的阶段,除了正常的position embedding、segment embedding,token embedding外,还增加了task embedding,用来区分训练的任务。但在fine-tuning阶段,可以使用任意值作为初始化。
Pre-training tasks
- 词法级别任务:大小写预测(对NER有用)、词频关系
- 语法级别任务:句子排序,让模型预测文章的句子属于哪种排序组合,就是多分类问题;句子距离预测:三分类问题(相邻,相同文章但不相邻,不同文章)
- 语义级别任务:三分类问题,0代表提问和标题强相关,1代表弱相关,2代表不相关
- 篇章句间关系任务:判断句子的语义关系,例如logical relationship。
- 信息检索关系任务:三分类。同语义级别。
模型输出:
