这里简单记录一下对话系统的各种领域,以及对应的代表论文。参考:https://zhuanlan.zhihu.com/p/83825070?utm_source=zhihu&utm_medium=social&utm_oi=697119379778727936
生成式对话
仍然是一个需要探索的领域,主要原因是,我们尽管可以将对话看作是seq2seq问题,但是这种闲聊对话其实其输出空间是非常大的,因此对于建模成生成问题来看的话,其实比较难。最主要的是缺少一个比较客观的自动评估策略。
不过,这次参加了一个百度的任务驱动型对话,尽管也算是闲聊,但是其闲聊是带着目的性的,即输出空间有限,因此可以使用生成式对话来解决。生成式对话,我们大多数时候可以参考翻译、文本摘要、语言模型等领域的比较典型的论文。
检索式对话
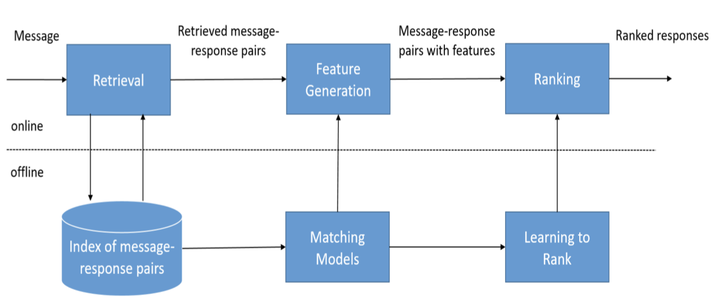
检索式对话是工业界比较偏爱的方法,可以用于解决闲聊型对话或FAQ问答型对话问题。FAQ通常是限定域的,比较容易解决,但对于闲聊型对话,即开放域,则需要大量的query-response pairs,即语料需要充足。随后,主要经历两个步骤。
召回
首先,在用神经网络深度匹配合适的回复之前,一般要先经过一个“粗筛”的模块召回若干相关的回复,减少q-r匹配的工作量。这个模块一般将用户当前轮的query与语料库里query进行快速匹配(当然你也可以加更多feature提高合适回复的召回率),得到几十上百个候选回复,完成第一轮的匹配。
因此这就要求q-q粗召模块比较轻量级,且匹配相关度比较好。因此我们可能需要检索模型BM25和一些轻量级文本特征表示模型如BOW。在开源文本匹配方面,可以使用百度的AnyQ开源工具。
精排
有了若干候选回复后,我们就需要一个精排模块来挑选合适的回复。这里主要的代表性工作,按照时间先后顺序有:
Multi-view: Multi-view response selection for human-computer conversation.
SMN:
DAM: Multi-turn response selection for chatbots with deep attention matching network
DGU: https://link.zhihu.com/?target=https%3A//github.com/baidu/Dialogue/tree/master/DGU
任务完成型对话
任务完成型对话的最终目标是完成任务,即需要在每一轮对话都采取合适的决策。这相当于一个多步决策求取reward(对话目标完成情况)最大化的问题,也就是强化学习的问题。(可惜,我没有学RL!!)但是,貌似RL在对话领域里还是有一定地位的,有机会再学习吧。
对话动作
用户发出的这个蕴含在自然语言中的命令就称为用户动作user action,我们可以将用户动作看做是用户输入的语义表示。因此,将用户动作从用户的自然语言文本甚至语音信号中解析出来的过程就称为自然语音理解(NLU)或口语理解(SLU)。
简单的想法是将每个action表示为全局唯一的id,但是action和action之间经常存在很深的耦合关系。比如”预定附近的椰子鸡“与”预定椰子鸡“之间是上下位关系,”预定西二旗附近的椰子鸡“与”预定西三旗附近的椰子鸡“有一个共同的”父action“——预定椰子鸡,我们采取的折中方式为“意图+槽位”,即用意图来表示一个模糊的目标,使用该意图预定义的一系列槽位来限制这个模糊目标,使得目标具体化。
例如:
1 | { |
完成这个自然语言输入到用户动作这种结构化语义表示(frame)的过程称为自然语言理解(NLU)。实际中,意图和槽位设计可能要复杂的多,比如有的槽位是不可枚举的(比如时间),槽位有冲突,甚至槽位内要嵌套槽位等,这些就要具体情况具体分析了。
理解用户输入
通常,我们默认一句话最多包含一个意图,因此可以将NLU任务中的意图识别看成简单的文本分类任务。
通常,我们在意图识别前,需要加一级领域分类,避免意图识别模型无法cover其他的领域。
而一个意图往往包含多个槽位,因此我们可以自然地将槽位解析任务建模为序列标注任务或者简化为文本多标签分类任务。由于意图识别和槽位解析任务息息相关,因此经常有将这两个任务进行join training的模型。
如今,意图识别与槽位解析的SOTA方法是百度对话团队的DGU,基于ERNIE2.0+处理多轮对话的精巧tricks刷爆了绝大多数对话任务。
记录对话状态
为了弄清楚用户的具体意图(把该填的槽填上,该解决的取值冲突解决掉),往往需要记下对话的关键信息,以供对话策略模块使用,帮助进行每一轮的决策。这里成为对话状态(dialogue state),完成其更新的过程称为对话状态追踪(dialogue state tracking,DST,又称 belief tracking)。
显然,对话状态的描述需要通过frame的方式来描述。而这种结构化的表示并不是在对话记录中显式存在的,很难通过大规模数据驱动的方法来学习记录对话状态的DST模型。
- 规则方法:最直接的一种策略是直接将NLU的输出结果(意图、槽位概率分布)离散化,直接取概率最高的意图、槽位作为本轮的用户动作,然后更新到DST模块中,这种方法适合DST的冷启动。显然,直接离散化最高概率的规则方法实现的DST会高度依赖NLU的准确性,且只能处理简单情况,并且在DST更新时会完全忽略已经积累的对话状态。所以,使用统计方法来建模ASR(语音识别)和NLU输出的不确定性是非常有必要的。
- 统计方法:构建DST数据集,使用有监督学习操作进行学习。比如利用分类器,或者建模成有监督的序列标注问题。然而,显然DST学习到的函数映射是基于NLU输出的概率分布的,一旦更新了NLU,则DST所熟悉的输入分布发生巨大改变,导致性能大打折扣。因此,自然的想法是让NLU和DST从pipeline结构变成端到端结构,即让用户自然语言输入直接连接到对话状态上,因此就可以将DST问题建模成“多轮分类”问题。DGU解决DST问题就会根据这种多轮分类的思路来做。
多轮决策完成对话目标
接下来,系统可以根据当前轮NLU模块解析出来的用户动作和积累的对话状态来完成相应的“推理”(称为对话策略模块),决定下一步是去澄清意图,say goodbye还是其他什么动作,并且后续NLG模块(自然语言生成)也会根据DP模块输出的对话决策(系统动作)来决定回复内容(即结构->文本)。
要完成对话目标,有监督学习对话策略是不靠谱的,所以对话策略的学习离不开RL。(又是我不会的,唉)经典代表作:A network-based end-to-end trainable task-oriented dialogue system
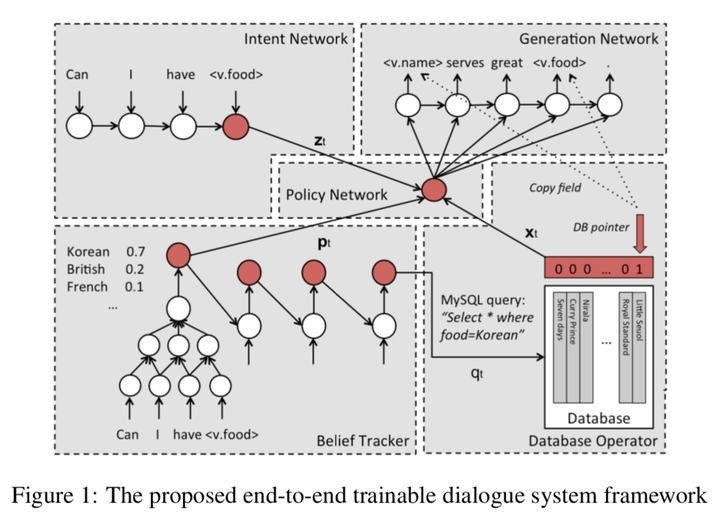
Belief Tracker:
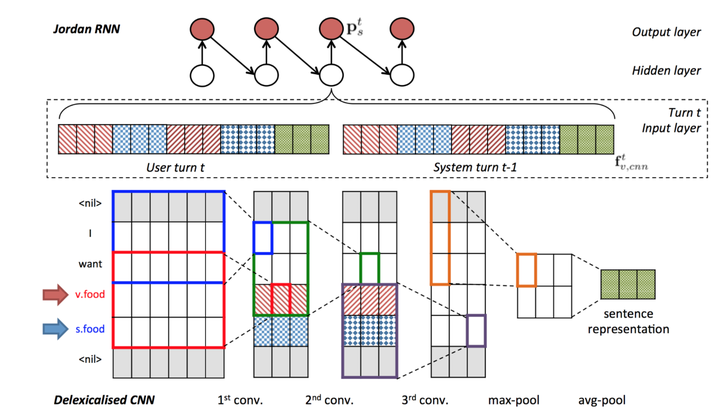
NLG
假如我们的pipeline系统终于可以作出合理决策(action)了。比如用户说,“好的,谢谢”,那么我们的系统经过语义理解、对话状态查询和作出决策,得出了“说再见”的系统动作,于是就要有一个模块将系统动作(即结构化语义表示)来翻译成自然语言输出“不客气哦,下次再见啦~”,完成这个结构->文本的模块就是自然语言生成(NLG)模块。
问题
- 多轮对话决策和单轮的意图识别的区别是什么?是因为要考虑上下文做一个更优决策吗?
最主要的是多轮对话涉及到意图的继承以及是否为开启一个新的意图