从现在开始,按照leetcode专题刷题。此博文持续更新。
注意点:
- 写完函数,该return的记得return!
- 不要丢三落四!!!
- 树,不仅要会递归写法,同·时也要会迭代写法。
操作系统相关
leetcode 146. LRU缓存机制
1 | class LRUCache { |
递归+回溯
汉诺塔
有三个柱子,分别为 from、buffer、to。需要将 from 上的圆盘全部移动到 to 上,并且要保证小圆盘始终在大圆盘上。
经典的递归问题,分为三步求解:
- 将n-1个圆盘从from -> buffer
- 将1个圆盘从from -> to
- 将n-1个圆盘从buffer->to
1 | void move(int n, char from, char buffer, char to){ |
leetcode 46*. 全排列
老是记不住!!!
1 | vector<vector<int>> permute(vector<int>& nums) { |
leetcode 17. 电话号码的字母组合
给定一个仅包含数字 2-9 的字符串,返回所有它能表示的字母组合。
给出数字到字母的映射如下(与电话按键相同)。注意 1 不对应任何字母。
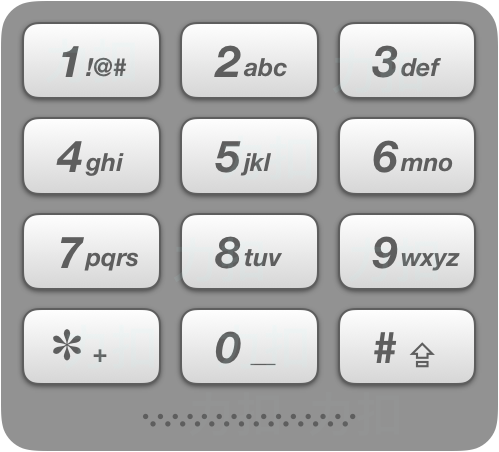
输入:“23”
输出:[“ad”, “ae”, “af”, “bd”, “be”, “bf”, “cd”, “ce”, “cf”].
思想:这道题和全排列有点像,也是用回溯。多记!!!
1 | vector<string> letterCombinations(string digits) { |
leetcode 22. 括号生成
给出 n 代表生成括号的对数,请你写出一个函数,使其能够生成所有可能的并且有效的括号组合。
例如,给出 n = 3,生成结果为:
1 | [ |
貌似懂了一点点。
1 | vector<string> generateParenthesis(int n) { |
链表
leetcode 19. 删除链表的倒数第N个节点
双指针。
1 | ListNode* removeNthFromEnd(ListNode* head, int n) { |
leetcode 141. 环形链表
1 | bool hasCycle(ListNode *head) { |
leetcode 反转链表
有多种出题的形式,第一种,将整个链表进行反转:
1 | ListNode* reverseList(ListNode* head){ |
第二种,反转链表的前n个元素(n <= 链表长度),需要记录后驱节点:
1 | ListNode *successor = NULL; // 后驱结点 |
第三种,反转链表的一部分:给一个索引区间[m,n](索引从1开始),仅仅反转区间中的链表元素:
1 | ListNode* reverseBetween(ListNode* head, int m, int n){ |
栈
leetcode 225. 用队列实现栈
只需要一个队列来模拟栈即可。要删除栈顶元素,可以用如下操作,即循环pop和push。获取top元素同理,但记得末尾要添加为temp。
2
3
4
5
6
7
8
9
10
> for (int i = 0; i < q.size() - 1; i++){
> q.push(q.front());
> q.pop();
> }
> int temp = q.front();
> q.pop();
> return temp;
> }
>
数组
leetcode 1. 两数之和
给定一个整数数组
nums和一个目标值target,请你在该数组中找出和为目标值的那 两个 整数,并返回他们的数组下标。
O(n)的做法,利用一个map来存储对应的值和下标,贴代码:
1 | map<int, int> hashmap; |
leetcode 3*. 找无重复字符的最长子串
不会做,这里要运用滑动窗口求解。
1 | map<char, int> M; |
leetcode 11. 盛最多水的容器
思路只差一点就做对了,加油啊!!有时候不要想得太多,先按照一开始的思路写写看。思想有点类似动态规划。
给你 n 个非负整数 a1,a2,…,an,每个数代表坐标中的一个点 (i, ai) 。在坐标内画 n 条垂直线,垂直线 i 的两个端点分别为 (i, ai) 和 (i, 0)。找出其中的两条线,使得它们与 x 轴共同构成的容器可以容纳最多的水。

代码:
1 | int maxArea(vector<int>& height) { |
leetcode 15*. 三数之和
给定一个包含 n 个整数的数组 nums,判断 nums 中是否存在三个元素 a,b,c ,使得 a + b + c = 0 ?找出所有满足条件且不重复的三元组。
注意:答案中不可以包含重复的三元组。
双指针:类似于滑动窗口题,需要先进行排序,再利用滑动窗口求解。但注意,由于不允许重复,因此在左右指针更新的时候,需要特别留意!
1 | class Solution { |
leetcode 16. 最接近的三数之和
方法与leetcode 15基本相同,同样是排序+滑动窗口。
leetcode 18. 四数之和
方法参考leetcode 15. 先进行排序,随后,我们首先将题目转化为三数之和,计算出新的target,从而可以求解。注意,仍然需要避免重复元素!!在每个循环初始化的时候,都要想清楚为什么。
还是不太会,这道题。。。希望不会出吧!有时间再做一次。
leetcode 31*. 下一个排列
实现获取下一个排列的函数,算法需要将给定数字序列重新排列成字典序中下一个更大的排列。
如果不存在下一个更大的排列,则将数字重新排列成最小的排列(即升序排列)。
必须原地修改,只允许使用额外常数空间。
以下是一些例子,输入位于左侧列,其相应输出位于右侧列。
1,2,3 → 1,3,2
3,2,1 → 1,2,3
1,1,5 → 1,5,1
参考思路:
- 判断按照字典序有木有下一个,如果完全降序(包括等号)就没有下一个,则要找第一个
- 如何判断有没有下一个呢?只要存在a[i-1]<a[i]的升序结构,则有下一个(我们要从右往左找)
- 当发现a[i-1]<a[i]的结构,则从[i, ]中找到最接近a[i-1]又大于a[i-1]的数字,由于降序,从右往左遍历即可得到k
- 交换a[i-1]和k,再对[i, ]进行排序。排序只需要首尾不停交换即可,因为已经是降序。
参考例子:比如[0,5,4,3,2,1],下一个是[1,0,2,3,4,5]
1 | // 简洁版答案 |
字符串
leetcode 5*. 最长回文子串
这道题,百看不会,所以还是要多做很多很多次。
给定一个字符串
s,找到s中最长的回文子串。你可以假设s的最大长度为 1000。
我记的是O(n^2)的做法,即遍历对称轴来找回文串:
1 | class Solution { |
还有更好的思路,马拉车算法O(N):https://blog.csdn.net/csdnnews/article/details/82920678
- 先对字符串进行预处理,两个字符之间加上特殊符号#;
- 然后遍历整个字符串,用一个数组来记录以该字符为中心的回文长度,为了方便计算右边界,我在数组中记录长度的一半(向下取整);
- 每一次遍历的时候,如果该字符在已知回文串最右边界的覆盖下,那么就计算其相对最右边界回文串中心对称的位置,得出已知回文串的长度;
- 判断该长度和右边界,如果达到了右边界,那么需要进行中心扩展探索。当然,如果第3步该字符没有在最右边界的“羽翼”下,则直接进行中心扩展探索。进行中心扩展探索的时候,同时又更新右边界;
- 最后得到最长回文之后,去掉其中的特殊符号即可。
leetcode 6*. Z字形变换
将一个给定字符串根据给定的行数,以从上往下、从左到右进行 Z 字形排列。
比如输入字符串为 “LEETCODEISHIRING” 行数为 3 时,排列如下:
L C I R
E T O E S I I G
E D H N
巧妙的思想,用一维数组就可以得到结果,图示如下:
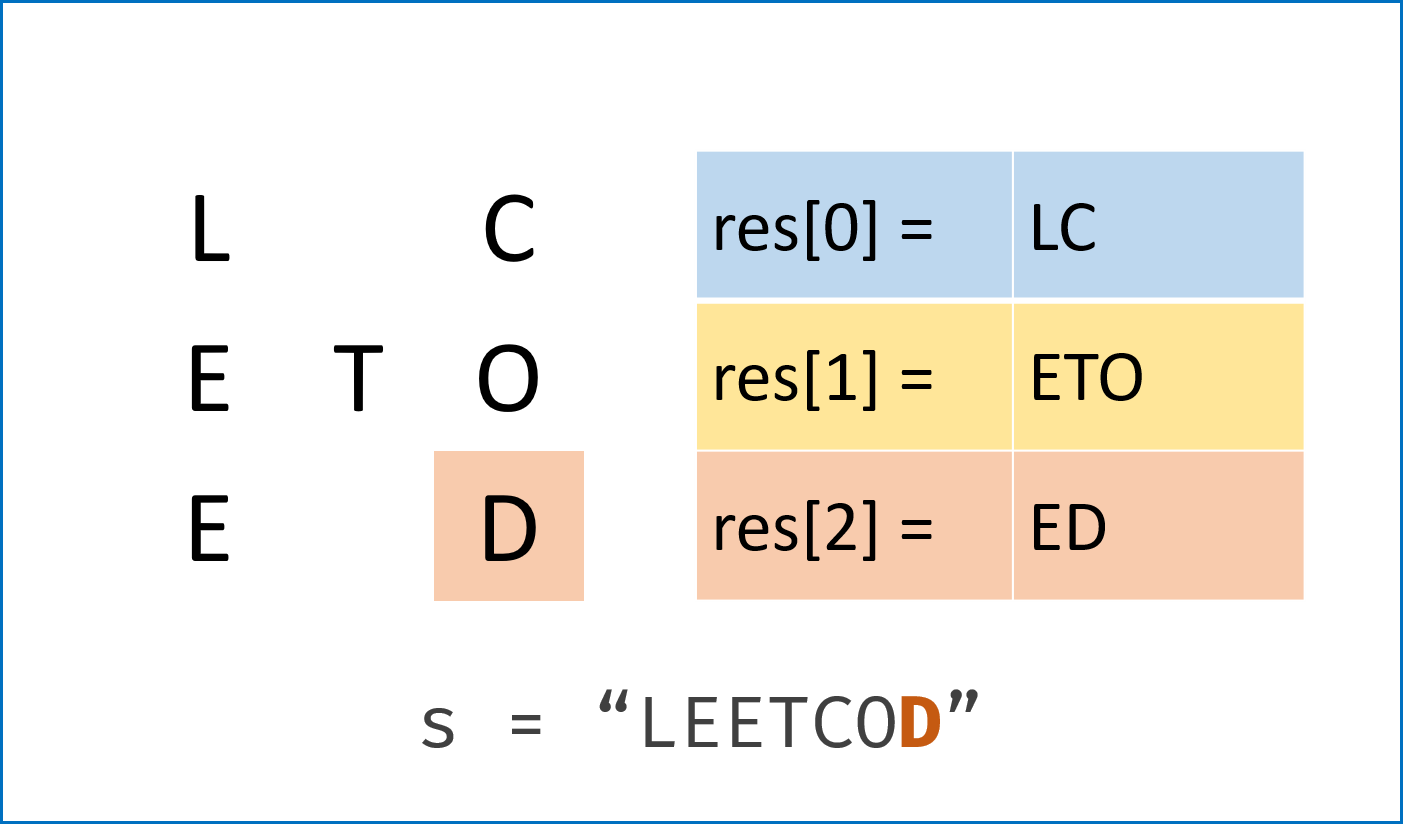
1 | string convert(string s, int numRows) { |
leetcode 8. 字符串转换整数(atoi)
请你来实现一个 atoi 函数,使其能将字符串转换成整数。
首先,该函数会根据需要丢弃无用的开头空格字符,直到寻找到第一个非空格的字符为止。
当我们寻找到的第一个非空字符为正或者负号时,则将该符号与之后面尽可能多的连续数字组合起来,作为该整数的正负号;假如第一个非空字符是数字,则直接将其与之后连续的数字字符组合起来,形成整数。
该字符串除了有效的整数部分之后也可能会存在多余的字符,这些字符可以被忽略,它们对于函数不应该造成影响。
注意:假如该字符串中的第一个非空格字符不是一个有效整数字符、字符串为空或字符串仅包含空白字符时,则你的函数不需要进行转换。
在任何情况下,若函数不能进行有效的转换时,请返回 0。
说明:
假设我们的环境只能存储 32 位大小的有符号整数,那么其数值范围为 [−231, 231 − 1]。如果数值超过这个范围,请返回 INT_MAX (231 − 1) 或 INT_MIN (−231) 。
示例 1:
输入: “42”
输出: 42示例 2:
输入: “ -42”
输出: -42
解释: 第一个非空白字符为 ‘-‘, 它是一个负号。
我们尽可能将负号与后面所有连续出现的数字组合起来,最后得到 -42 。示例 3:
输入: “4193 with words”
输出: 4193
解释: 转换截止于数字 ‘3’ ,因为它的下一个字符不为数字。示例 4:
输入: “words and 987”
输出: 0
解释: 第一个非空字符是 ‘w’, 但它不是数字或正、负号。
因此无法执行有效的转换。示例 5:
输入: “-91283472332”
输出: -2147483648
解释: 数字 “-91283472332” 超过 32 位有符号整数范围。
因此返回 INT_MIN (−231) 。
这个问题其实没有过多的技巧,考察的是细心和耐心,并且需要不断地调试。在这里我简单罗列几个要点。
Java 、Python 和 C++ 字符串的设计都是不可变的,即使用 trim() 会产生新的变量,因此我们尽量不使用库函数,使用一个变量 index 去做线性遍历,这样遍历完成以后就得到转换以后的数值。
- 根据示例 1,需要去掉前导空格;
- 根据示例 2,需要判断第 1 个字符为 + 和 - 的情况,因此,可以设计一个变量 sign,初始化的时候为 1,如果遇到 - ,将 sign 修正为 -1;
- 判断是否是数字,可以使用字符的 ASCII 码数值进行比较,即 0 <= c <= ‘9’;
- 根据示例 3 和示例 4 ,在遇到第 1 个不是数字的字符的情况下,就得退出循环;
- 根据示例 5,如果转换以后的数字超过了 int 类型的范围,需要截取。这里需要将结果 res 变量设计为 long 类型,注意:由于输入的字符串转换以后也有可能超过 long 类型,因此需要在循环内部就判断是否越界,只要越界就退出循环,这样也可以减少不必要的计算;
- 因为涉及下标访问,因此全程需要考虑数组下标是否越界的情况。
特别注意:由于题目中说“环境只能保存 32 位整数”,因此这里在每一轮循环之前先要检查乘以 1010 以后是否溢出,具体细节请见编码.
这里贴一下判断函数:
1 | if (res > INT_MAX / 10 || (res == INT_MAX / 10 && (currChar - '0') > INT_MAX % 10)){ |
leetcode 10*. 正则表达式匹配(困难)
1 | bool isMatch(string s, string p) { |
leetcode 12. 整数转罗马数字
使用两个数组,存储对应的string和代表的数字。虽然再对num进行转换即可。
leetcode 13. 罗马数字转整数
使用
leetcode 14. 最长公共前缀
我的做法:先求出所有字符串中的最短长度,再遍历字符串来判断。时间复杂度相当于:字符串总数 * 最短字符串长度。
用python的话很简单诶,复杂度只有O(N),求出最短的和最长的两个字符串,再比较他们的最长公共前缀即可。
动态规划
我的弱点之一。
leetcode 10*. 正则表达式匹配
给你一个字符串
s和一个字符规律p,请你来实现一个支持'.'和'*'的正则表达式匹配。
2
3
> '*' 匹配零个或多个前面的那一个元素
>
递归
1 | bool isMatch(string s, string p) { |
leetcode 53. 最大子序和
给定一个整数数组 nums ,找到一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。
示例:
输入: [-2,1,-3,4,-1,2,1,-5,4],
输出: 6
解释: 连续子数组 [4,-1,2,1] 的和最大,为 6。
首先,来理解最标准的动态规划做法。
初始化一个dp数组,用来存储当前数组位置所对应的最大和。其中,初始状态为dp[0] = nums[0]。状态转移方程为:dp[i] = max(0, dp[i-1]) + nums[i]。
1 | int maxSubArray(vector<int>& nums) { |
从状态转移方程可以看到,dp[i] = max(dp[i - 1], 0) + nums[i]看出,当前状态的值只取决于前一个状态值,所以我们可以用一个变量来代替dp[i-1]:
1 | int maxSubArray(vector<int>& nums) { |
leetcode 62. 不同路径
一个机器人位于一个 m x n 网格的左上角 (起始点在下图中标记为“Start” )。
机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为“Finish”)。
问总共有多少条不同的路径?
使用二维数组作为状态方程,表示到达该位置的路径数。其中,初始状态,第一行和第一列的值为1。接着需要设计状态转移方程,其实通过观察也可以发现:dp[i][j] = dp[i-1][j] + dp[i][j-1]。(要努力培养这种思维,即如何利用之前已经获得的值呢?)
1 | int uniquePaths(int m, int n) { |
leetcode 63*. 不同路径II
同样使用动态规划来做,做法和62基本相同。不同之处在于,多了障碍物,所以初始化的时候需要注意:
1 | int flag = 0; |
状态转移方程和之前一致。另外要注意,如果我们的dp数组用int来存值,那么在中间会有计算结果超过int值表示。因此要修改成dp数组改成long表示。
另外,用vector初始化二维数组:
1 | vector<vector<int>> v(rows, vector<int>(cols, 0)); |
leetcode 64. 最小路径和
还是比较简单的。我使用二维数组来做dp数组,状态转移方程为:
1 | dp[i][j] = min(dp[i-1][j], dp[i][j-1]) + grid[i][j]; |
leetcode 70. 爬楼梯
其实是斐波那契数列题,也可以用动态规划的思想来理解。91题的思想要从这道题参考。
leetcode 91*. 解码方法
一条包含字母 A-Z 的消息通过以下方式进行了编码:
‘A’ -> 1
‘B’ -> 2
…
‘Z’ -> 26
给定一个只包含数字的非空字符串,请计算解码方法的总数。示例 1:
2
3
4
> 输出: 2
> 解释: 它可以解码为 "AB"(1 2)或者 "L"(12)。
>
>
示例 2:
2
3
4
> 输出: 3
> 解释: 它可以解码为 "BZ" (2 26), "VF" (22 6), 或者 "BBF" (2 2 6) 。
>
这一题,我做了很多次,但是都是错的。原因有两个:
- 将动态规划的思想给搞错了,没有体会题目的含义;
- 没有注意到0这个边界条件的额外处理。
正确的思路是这样的:
我们知道最后一个字母有可能是由一个数字串或两个数字串转化而来,例如’12312’这个数字串,转化成字母串最后一位可以是’2’转成B,也可能是’12’转成L。
这就有点类似跳台阶问题。设数字串S的前i个数字解密成字母串有dp[i]种方式:那么就有dp[i] = dp[i-1] + dp[i-2]。
dp[i-1]表示最后一个数字解码成一个字母;
dp[i-2]表示最后两个数字解码成一个字母。
而我的错误,就是没有看清楚本质,而是一直在处理各种边界条件的情况下死磕着,这是非常错误的!!通常情况下,状态转移方程不会有过多复杂的情况(正则表达式那一题除外)。因此,要自己认真体会!!
1 | // dp[i + 1] = dp[i] + dp[i - 1]; |
leetcode 96*. 不同的二叉搜索树
要知道怎么找规律。我们设$G(n)$代表n个整数为节点构成的二叉搜索树个数。其中,令$f(i)$表示第i个结点为根的二叉搜索树个数,则有:
而$f(i)$又可以表示为以i为根节点,再结合左右子树的值:
因此有:
贴贴代码:
1 | int numTrees(int n) { |
leetcode 120. 三角形最小路径和
给定一个三角形,找出自顶向下的最小路径和。每一步只能移动到下一行中相邻的结点上。例如,给定三角形:
1 | [ |
自顶向下的最小路径和为 11(即,2 + 3 + 5 + 1 = 11)。
思路:使用二维dp数组,先初始化后,根据状态转移方程进行更新。
1 | if (j == 0) { // 第0列 |
之后,再找最后一行的最小值即可。另外,上述代码是自顶向下求;而自底向上求会更加方便,因为dp[i][j] = min(dp[i+1][j], dp[i+1][j+1]) + triangle[i][j]必成立,不需要额外判断。另外,还可以在原输入的基础上修改,做到空间复杂度为O(1)。
贴代码:
1 | // 一维dp数组 |
leetcode 312*. 戳气球(困难)
有
n个气球,编号为0到n-1,每个气球上都标有一个数字,这些数字存在数组nums中。现在要求你戳破所有的气球。每当你戳破一个气球 i 时,你可以获得 nums[left] nums[i] nums[right] 个硬币。 这里的 left 和 right 代表和 i 相邻的两个气球的序号。注意当你戳破了气球 i 后,气球 left 和气球 right 就变成了相邻的气球。
求所能获得硬币的最大数量。
说明:
- 你可以假设 nums[-1] = nums[n] = 1,但注意它们不是真实存在的所以并不能被戳破。
- 0 ≤ n ≤ 500, 0 ≤ nums[i] ≤ 100
示例:
输入: [3,1,5,8]
输出: 167
解释: nums = [3,1,5,8] —> [3,5,8] —> [3,8] —> [8] —> []
coins = 315 + 358 + 138 + 181 = 167
记录一道困难的动态规划题,貌似网易很喜欢出。
动态规划:
经过一连串的分析(其实我看不太懂这个分析)https://qoogle.top/leetcode-312-burst-balloons/ 总之,代码如下:
1 | vector<vector<int>> dp; |
322. 零钱兑换
给定不同面额的硬币 coins 和一个总金额 amount。编写一个函数来计算可以凑成总金额所需的最少的硬币个数。如果没有任何一种硬币组合能组成总金额,返回 -1。
示例1:
1 | 输入:coins = [1,2,5], amount = 11 |
思想:我总想着怎么用贪心来解,殊不知,这是一道动态规划题。。。
1 | int coinChange(vector<int>& coins, int amount) { |
leetcode 121. 买卖股票的最佳时机
给定一个数组,它的第 i 个元素是一支给定股票第 i 天的价格。
如果你最多只允许完成一笔交易(即买入和卖出一支股票),设计一个算法来计算你所能获取的最大利润。
注意你不能在买入股票前卖出股票。
示例1:
1 | 输入: [7,1,5,3,6,4] |
思路:动态规划。如果直接计算最大差值的话应该会超时。机灵一点!!!
1 | int maxProfit(vector<int>& prices) { |
122. 买卖股票的最佳时机II
给定一个数组,它的第 i 个元素是一支给定股票第 i 天的价格。
设计一个算法来计算你所能获取的最大利润。你可以尽可能地完成更多的交易(多次买卖一支股票)。
注意:你不能同时参与多笔交易(你必须在再次购买前出售掉之前的股票)。
示例1:
1 | 输入: [7,1,5,3,6,4] |
一直在想着要怎么用动态规划,万万没想到,这道题却是脑筋急转弯。。。
1 | [7, 1, 5, 6] 第二天买入,第四天卖出,收益最大(6-1),所以一般人可能会想,怎么判断不是第三天就卖出了呢? 这里就把问题复杂化了,根据题目的意思,当天卖出以后,当天还可以买入,所以其实可以第三天卖出,第三天买入,第四天又卖出((5-1)+ (6-5) == 6 - 1)。所以算法可以直接简化为只要今天比昨天大,就卖出。 |
1 | int maxProfit(vector<int>& prices){ |
链表
leetcode 206. 反转链表
今天,一直不擅长的题目做出来了!(也可能是因为之前做过)我的体会是,可以用画图的方式来看答案,就是自己摸清楚需要记录什么结点,结点之间的关系怎么变换,应该就可以懂了。
1 | // 迭代做法 |
leetcode 203 删除链表中等于给定值val的所有节点
1 | ListNode* removeElements(ListNode* head, int val) { |
二叉树
二叉树的题,都直接重新刷一遍。
leetcode 112. 路径总和
给定一个二叉树和一个目标和,判断该树中是否存在根节点到叶子节点的路径,这条路径上所有节点值相加等于目标和。
1 | bool hasPathSum(TreeNode* root, int sum) { |
leetcode 94*. 二叉树的中序遍历
递归做法:
1 | vector<int> res; |
非递归,利用栈来做。看看代码就会理解!!!
1 | vector<int> inorderTraversal(TreeNode* root) { |
补充:前序遍历非递归写法
1 | vector<int> preorderTraversal(TreeNode* root) { |
与中序遍历非递归的不同点,在于访问结点的位置不同。前序遍历是在入栈时就访问,中序遍历是在出栈时访问。
补充:后序遍历非递归写法
1 | vector<int> postorderTraversal(TreeNode* root) { |
leetcode 95*. 不同的二叉搜索树II
不太会,看答案。
1 | vector<TreeNode*> generateTrees(int n) { |
leetcode 98. 验证二叉搜索树
有两个地方要注意:
- 不能出现相等的数字!
- 空节点也返回true,算是二叉搜索树。
第一种方法是通过中序遍历把结果保存到vector中,再依次判断;第二种方法是空间复杂度为O(1),即边中序遍历边判断。但是,有边界值需要考虑!!!
1 |
|
leetcode 99*. 恢复二叉搜索树
二叉搜索树中的两个节点被错误地交换。请在不改变其结构的情况下,恢复这棵树。
示例1:
输入: [1,3,null,null,2]
1
/
3
\
2
输出: [3,1,null,null,2]
3
/
1
\
2
感觉我有点被这个“困难”题给吓到了,所以并没有去思考思路。但是看了别人的答案后,发现其实是一道很简单的题。(事实证明,还是不懂)贴代码吧。。。
1 | TreeNode *t1, *t2, *pre; //记得每个都要加星号! |
leetcode 100. 相同的树
按照最简单的思维去思考!不要想得太复杂!
1 | bool isSameTree(TreeNode* p, TreeNode* q) { |
leetcode 101*.对称二叉树
给定一个二叉树,检查它是否是镜像对称的。
例如,二叉树 [1,2,2,3,4,4,3] 是对称的。
1 | 1 |
但是下面这个 [1,2,2,null,3,null,3] 则不是镜像对称的:
1 | 1 |
递归,多思考一下就能想出来:
1 | bool isSymmetric(TreeNode* root) { |
坑爹的是,自己写了很久的迭代写法,但是一直都是错的。就是利用队列层次遍历的那种常规操作,写出来的结果一直不对。最后,只能参考官方教程的做法, 当然,这样做其实效率更高,空间也用的少。
1 | bool isSymmetric(TreeNode* root){ |
leetcode 102. 二叉树的层次遍历
给定一个二叉树,返回其按层次遍历的节点值。 (即逐层地,从左到右访问所有节点)。返回类型为vector
1 | vector<vector<int>> levelOrder(TreeNode* root) { |
leetcode 105*. 从前序与中序遍历序列构造二叉树
我之前在牛客做过,一直写的方法是利用构造多个vector序列。但是实际上这么写,空间和时间都有很大的复杂度!!!所以,今天看到了利用了hashmap的方法,特此记录。
1 | vector<int> preorder, inorder; |
leetcode 106*. 从中序与后序遍历序列构造二叉树
这一题与前一题基本类似,同样用hashmap来加快时间效率。然而!!!在创建左右子树的时候,应当先创建右子树,再创建左子树(因为后序遍历的尾巴就先是右子树),不然会出错!!!
而由前序和中序构造二叉树,则要先创建左子树,再创建右子树!!!
leetcode 108*. 将有序数组转换为二叉搜索树
转换后的二叉搜索树需要是高度平衡二叉树。没有思路,但是看了答案后发现其实很简单。从有序数组的中间部分划分左右子树,就可以确保二叉搜索树是高度平衡的了!!要注意一点,中间部分对于偶数长度的数组来说,可能选左边的,也可能选右边的,所以答案的结果不唯一。
1 | TreeNode* sortedArrayToBST(vector<int>& nums) { |
leetcode 110*. 平衡二叉树
判断是否为平衡二叉树。我一开始是跟着自己在牛客网写的代码那样的写法来写,但是始终过不了leetcode的样例。后来,真相大白,我的代码确实有错误!!这也说明,牛客的样例和leetcode的样例相比不够全。
1 | bool isBalanced(TreeNode* root) { |
leetcode 109*. 有序链表转换二叉搜索树
这道题和108题有点类似,区别是输入不再是数组,而是一个升序链表。我一开始是将链表中的元素取出来放到数组中,再按照108题做,然而,运行效率和空间复杂度太高了!
实际上,我们可以按照那道题的思想,找出链表里中点的位置,再进行指针的转换。
1 | TreeNode* sortedListToBST(ListNode* head){ |
leetcode 222
求完全二叉树的节点个数。
1 | int countNodes(TreeNode* root) { |
leetcode 72. 编辑距离
给定两个单词 word1 和 word2,计算出将 word1 转换成 word2 所使用的最少操作数 。
你可以对一个单词进行如下三种操作:
- 插入一个字符
- 删除一个字符
- 替换一个字符
示例 1:
输入: word1 = “horse”, word2 = “ros”
输出: 3
解释:
horse -> rorse (将 ‘h’ 替换为 ‘r’)
rorse -> rose (删除 ‘r’)
rose -> ros (删除 ‘e’)示例 2:
输入: word1 = “intention”, word2 = “execution”
输出: 5
解释:
intention -> inention (删除 ‘t’)
inention -> enention (将 ‘i’ 替换为 ‘e’)
enention -> exention (将 ‘n’ 替换为 ‘x’)
exention -> exection (将 ‘n’ 替换为 ‘c’)
exection -> execution (插入 ‘u’)
1 | int minEditDistance(string word1, string word2) { |
数学
leetcode 29. 两数相除
给定两个整数,被除数 dividend 和除数 divisor。将两数相除,要求不使用乘法、除法和 mod 运算符。返回被除数 dividend 除以除数 divisor 得到的商。
思路:很不擅长这类限制使用运算符的题目。参考他人的写法:
1 | int divide(int dividend, int divisor) { |
633. 平方数之和
给定一个非负整数
c,你要判断是否存在两个整数a和b,使得 a2 + b2 = c。
用滑动窗口来做。但是,这道题有点坑,主要是在int类型上可能会超,因此要自己学会判断。
1 | bool judgeSquareSum(int c){ |
排序
面试题10.01. 合并排序的数组
给定两个排序后的数组 A 和 B,其中 A 的末端有足够的缓冲空间容纳 B。 编写一个方法,将 B 合并入 A 并排序。
初始化 A 和 B 的元素数量分别为 m 和 n。
示例:
1 | 输入: |
我被自己愚蠢到了。一直想着,把A数组中的数字先往后挪,再利用归并排序从头开始填入数字,然而,这样做在挪数字时会出现很多的错误。其实,从A数组末尾开始比较着填数字就好了,是我太傻了。
1 | void merge(vector<int>& A, int m, vector<int>& B, int n) { |
BFS
BFS通常用来求解最短路径问题。要学会“抽象”问题。
leetcode 127. 单词接龙
给定两个单词(beginWord 和 endWord)和一个字典,找到从 beginWord 到 endWord 的最短转换序列的长度。转换需遵循如下规则:每次转换只能改变一个字母, 转换过程中的中间单词必须是字典中的单词。
说明: 如果不存在这样的转换序列,返回 0; 所有单词具有相同的长度 ;所有单词只由小写字母组成 ;字典中不存在重复的单词。你可以假设 beginWord 和 endWord 是非空的,且二者不相同。
示例 1:
输入:
beginWord = “hit”,
endWord = “cog”,
wordList = [“hot”,”dot”,”dog”,”lot”,”log”,”cog”]
输出: 5
解释: 一个最短转换序列是 “hit” -> “hot” -> “dot” -> “dog” -> “cog”,
返回它的长度 5。
思路:这一题就是需要有抽象思维。每个单词是一个结点,只有相差一个字符的点之间才有路径,路径权值全部为1. 本质就是求图的两点最短路径问题!!!因此,用BFS来做最为合适。
leetcode 994*. 腐烂的橘子
在给定的网格中,每个单元格可以有以下三个值之一:
值 0 代表空单元格;
值 1 代表新鲜橘子;
值 2 代表腐烂的橘子。
每分钟,任何与腐烂的橘子(在 4 个正方向上)相邻的新鲜橘子都会腐烂。
返回直到单元格中没有新鲜橘子为止所必须经过的最小分钟数。如果不可能,返回 -1。
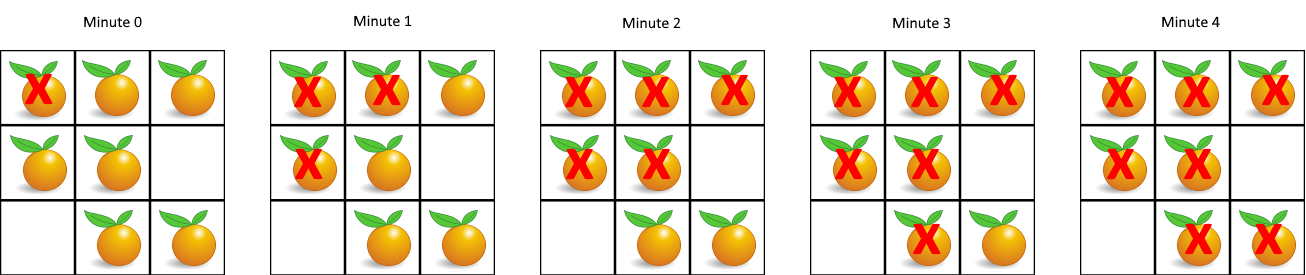
思路:这道题应该用广度优先遍历(虽然我一开始没有看出来)。这里类似于树的广度遍历:
1 | int orangesRotting(vector<vector<int>>& grid) { |
111. 二叉树的最小深度
用BFS来求。一旦遍历到左右子树均为空的结点,则返回当前深度。
也可以递归来做:
1 | int minDepth(TreeNode* root){ |
DFS
leetcode 200. 岛屿数量
给定一个由 ‘1’(陆地)和 ‘0’(水)组成的的二维网格,计算岛屿的数量。一个岛被水包围,并且它是通过水平方向或垂直方向上相邻的陆地连接而成的。你可以假设网格的四个边均被水包围。
示例 1:
1 | 输入: |
标准DFS,但是很多细节要注意啊!!!另外,可以不用辅助数组就不用!!!
1 | class Solution { |
leetcode 130. 被围绕的区域
给定一个二维的矩阵,包含 'X' 和 'O'(字母 O)。
找到所有被 'X' 围绕的区域,并将这些区域里所有的 'O' 用 'X' 填充。
1 | X X X X |
运行后变为:
1 | X X X X |
思路:其实,这道题要学会换个思路。我们不应该一直想着怎么求出被‘X’围绕的区域,而是可以从边界上的’O’来下手,这样就可以用普通的BFS或者DFS方法来做了!这里就不贴代码了,用DFS来做比较简单。
贪心
leetcode 452. 用最少数量的箭引爆气球
在二维空间中有许多球形的气球。对于每个气球,提供的输入是水平方向上,气球直径的开始和结束坐标。由于它是水平的,所以y坐标并不重要,因此只要知道开始和结束的x坐标就足够了。开始坐标总是小于结束坐标。平面内最多存在104个气球。
一支弓箭可以沿着x轴从不同点完全垂直地射出。在坐标x处射出一支箭,若有一个气球的直径的开始和结束坐标为 xstart,xend, 且满足 xstart ≤ x ≤ xend,则该气球会被引爆。可以射出的弓箭的数量没有限制。 弓箭一旦被射出之后,可以无限地前进。我们想找到使得所有气球全部被引爆,所需的弓箭的最小数量。
Example:
1 | 输入: |
思路:贪心思想。先按照气球的x_end坐标由小到大排序。然后再查看接下来气球的x_start是否大于这个first_end.
1 | int findMinArrowShots(vector<vector<int>>& points) { |
其他
leetcode 54. 螺旋矩阵
1 | vector<int> spiralOrder(vector<vector<int>>& matrix) { |
额外找:
5 一个数组a,判断是否存在i<j<k, a[i]<a[k]<a[j](撕代码)
6 找到一个字符串中不重复子串的最大长度(撕代码)
7 一个二叉搜索树,找出小于m的最大数(撕代码)
算法题:两个有序数组求交集
给定一个表,列名如下,
user | video | time
查询每个用户第二个看得视频,请写出sql语句。
作者:Johnny想要offer
https://www.nowcoder.com/discuss/199615来源:牛客网
一道基于抖音的sql题目:
给定一个表,列名如下,
user | video | time
查询每个用户第二个看得视频,请写出sql语句。
写出统计用户数量的sql语句。
2 交叉熵损失函数公式怎么写
3 最大似然估计公式
4 梯度爆炸lstm怎么解决
5 一个数组a,判断是否存在i<j<k, a[i]<a[k]<a[j](撕代码)
6 找到一个字符串中不重复子串的最大长度(撕代码)
7 一个二叉搜索树,找出小于m的最大数(撕代码)
8 linux找上一个使用命令
9 vim定位到第一行
千万向量中找到和单个向量相似的那个,先聚类,再然后输入向量先与聚类中心比较再与类中的向量比较。
模型为了拟合数据而调节参数改变模型形状,正则则是使得模型形状更为平缓,使得泛化能力增加,而bias则只会使得模型平移,因此正则bias应该没什么效果
transformer结构
既然LR解决的是分类问题,它为什么叫逻辑回归